- Traditional machine learning models require training from scratch, which requires a large amount of data to achieve high performance.
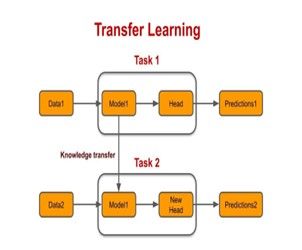
On the other side, transfer learning involves using knowledge gained from one task to improve learning on a different but related task is efficient and helps achieve better results using a small data set.
- In traditional machine learning, feature extraction, and model training are done simultaneously; that is, each model is trained for a specific purpose, and this model learns to make predictions based on the features present in the training data. On the other hand, in transfer learning, instead of starting from scratch, pre-trained models are used as a starting point, and their learned representations are adapted to the new task.
- In traditional machine learning, the optimal performance is slow compared to that of transfer learning models. This is because the models already understand the feature, and this makes them faster than training neural networks from scratch.
- Traditional ML models require a substantial amount of data.
On the other hand, in transfer learning, there is limited data for the new task or when training from scratch is computationally expensive. - Examples of traditional ML algorithms include decision trees, support vector machines (SVM), k-nearest neighbors (KNN), and logistic regression. Common techniques in transfer learning include fine-tuning pre-trained models, feature extraction, and domain adaptation.
- Healthcare: Transfer learning is used as the pre-trained model for image analysis, which can aid in diagnosing diseases from medical images.
- Finance: the models of transfer learning are trained in historical data and can assist in predicting market trends or detecting fraudulent transactions.
- Natural language processing: the pre-trained language models can enhance chatbots' conversational abilities or sentiment analysis.
- Cybersecurity: transfer learning aids in identifying malicious activities based on patterns learned from previous attacks and these are done by the pre-trained models.
- Driving: Transfer learning enhances the perception systems of self-driving cars by using pre-trained models to recognize objects, pedestrians, and road signs in various driving conditions.
- Agriculture: Transfer learning helps analyze satellite and drone imagery to monitor crop health, detect diseases, and estimate yields, aiding farmers in making informed decisions.
Pretrained models are machine learning models that have been trained on a large dataset for a particular task, such as image recognition or natural language understanding, by experts or organizations. Pre-trained models are used as a starting point for developing machine learning models, as they provide a set of initial weights and biases that can be fine-tuned for a specific task. Pretrained models include language models, object detection models, and image classification models. Convolutional neural networks (CNNs) are typical for image classification, while region-based CNNs (R-CNNs) are used for object recognition. Recurrent neural networks (RNNs) or transformers are typical for language models, predicting the next word in a sequence.
Pretrained models use knowledge gained from large data sets and transfer it to solve related tasks with limited data or computational resources.
It all starts with:
1. Initial Training:
- Data collection: The model is first trained on a vast and diverse dataset. For example, an image classification model might be trained on millions of images from ImageNet, covering thousands of categories.
- Model Design: The model's structure (like CNNs for images or transformers for text) is made to find meaningful patterns. CNNs identify basic shapes and textures, while transformers understand word relationships and context.
- Training Process: Using this large dataset, the model undergoes extensive training, adjusting its internal parameters (weights and biases) to minimize prediction errors.
2. Knowledge Encoding:
- Feature Extraction: The model learns to pick out key features from the data. For example, in images, early layers of a CNN detect simple things like edges, while later layers identify complex objects.
- Understanding Context: In language models like BERT, the model learns the meaning of words based on their context in sentences.
3. Transfer Learning:
- Model Adaptation: The pre-trained model can be modified for new tasks. This can be done by fine-tuning or using it to extract features.
- Fine-tuning: The model is slightly adjusted with a smaller dataset specific to the new task, like recognizing diseases in X-rays.
- Feature Extraction: The model's learned features are used to help another model make predictions on new data.
VGG (Visual Geometry Group) is a neural network architecture known for its simplicity in image classification tasks. It works by looking at many different parts of the picture and then deciding what's most important. VGG is characterized by its deep structure, typically with 16 or 19 layers, which allows it to capture intricate features in images. Despite its simplicity, VGG has shown strong performance on various computer vision tasks.
ResNet-50: It is also a neural network that is commonly used for image classification tasks. It consists of 50 layers and employs residual connections, allowing for deeper networks without suffering from the vanishing gradient problem. ResNet-50 has been pre-trained on large image datasets like ImageNet, so it knows a lot about different things in pictures. Due to its strong performance and efficient training characteristics, it is often used as a base model for transfer learning in computer vision applications.
Google's MobileNet: MobileNet is a lightweight convolutional neural network (CNN) architecture designed by Google for mobile and embedded vision applications or we can say it is like a smaller, more efficient brain for recognizing things in pictures. It's designed to work for low computational resources and memory footprint, making it suitable for devices with limited power, such as smartphones and IoT devices. MobileNet uses a special technique called depthwise separable convolutions to be fast and save memory. It's commonly used for tasks like image classification, object detection, and face recognition on mobile devices.
Google's NASNet: Google's NASNet (Neural Architecture Search Network) is an innovative neural network architecture designed using reinforcement learning. It does this by trying out lots of different designs using this method. This means it can find the best designs without needing humans to manually test each one. NASNet has been successful in numerous tasks such as object detection and semantic segmentation, showcasing its versatility and effectiveness.