Logistic regression is a machine learning algorithm used for binary classification tasks. It uses a sigmoid function to predict the probability of a certain event occurring. The sigmoid function maps any input to a value between 0 and 1. It models the relationship between the dependent variable (binary outcome) and one or more independent variables by using the logistic function. This algorithm is widely used in various domains such as healthcare, finance, and marketing.
Support Vector Machines (SVM) are supervised learning models used for classification and regression tasks in machine learning. They work by finding the best line (or boundary) that separates different groups in the data. This line keeps the groups as far apart as possible. SVMs are effective in high-dimensional spaces and can handle both linear and non-linear data using kernel functions. They are popular because they are accurate and reliable for many tasks.
K-Nearest Neighbors (KNN) is a handy tool in machine learning for figuring out what category (classification) or value something belongs to (regression tasks). It works by finding the K closest data points (neighbors) to a given query point in feature space.
• For classification, the majority class among the K neighbors determines the class of the query point.
• For regression, the average or weighted average of the target values of the K neighbors predicts the target value of the query point.
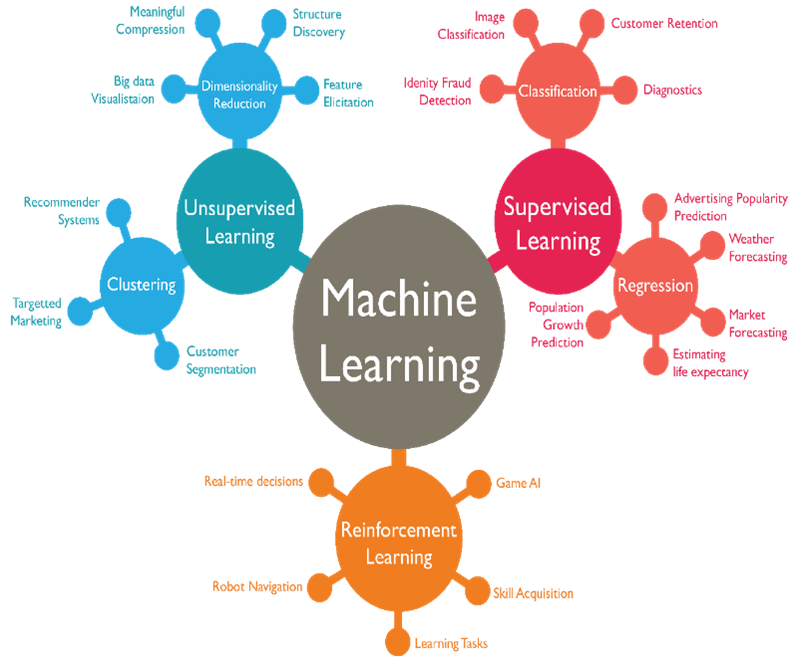
Principal Component Analysis (PCA) is a dimensionality reduction method in machine learning that is often used to reduce the number of variables in a dataset, by transforming a large set of variables into a smaller while retaining most of the important information. It works by transforming the original variables into a new set of variables called principal components, which are uncorrelated and ordered by the amount of variance they capture from the data. This makes the data easier to understand and work with and can also help other machine learning methods perform better by focusing on the most important parts of the data.
Gradient Boosting Machines (GBMs) are powerful machine learning algorithms used for both classification and regression tasks. This is done by combining the predictions of multiple weak models to make a stronger prediction. It works by training weak models sequentially, where each new model corrects errors made by the previous ones. The weak models are typically decision trees, and the process is called gradient boosting because it involves minimizing a loss function using gradient descent. They are widely used for their accuracy and effectiveness in various tasks, like ranking, predicting, and identifying trends.
Naive Bayes is a simple and powerful algorithm used in machine learning for sorting things into categories. It assumes that all the features are independent and uses Bayes’ theorem to predict the probability of a certain class.
Bayes’ Theorem: Bayes’ theorem states that the probability of an event occurring is equal to the prior probability of the event occurring multiplied by the likelihood of the event given certain evidence.
Naive Bayes calculates the probability of each class based on the input features and predicts the class with the highest probability. It's commonly used in spam detection, sentiment analysis, and text classification.
A decision tree in machine learning is a model used for classification and regression tasks. It begins with a root node, which has no incoming branches. The branches extending from the root node lead to internal nodes, also known as decision nodes. These nodes split the data based on feature values, creating a tree-like structure of decisions. Both types of nodes evaluate the available features to form homogenous subsets, represented by leaf nodes or terminal nodes. These leaf nodes indicate all possible outcomes within the dataset. Decision trees are easy to interpret and can manage both numerical and categorical data.
A random forest is a machine learning method used for tasks like classifying data and making predictions. In this algorithm many decision trees are trained, and their predictions are combined to make a more accurate prediction. Each tree is trained on a random subset of the data and features, which introduces diversity and reduces variance. By using many trees together, random forests give strong, accurate results and are less likely to overfit than single decision trees as the prediction is obtained by averaging the predictions of all the trees.
A neural network is an artificial intelligence method that enables computers to process data in a manner inspired by the human brain. It comprises interconnected nodes, or neurons, arranged in layers: input, hidden, and output. Each connection has a weight that adjusts as the network learns from data. Deep Learning, a subset of machine learning, utilizes multi-layered artificial neural networks to learn and make decisions. Neural networks are widely used in image and speech recognition, natural language processing, and various other applications due to their ability to model complex relationships in data.
Recurrent Neural Networks (RNNs) are a type of artificial neural network designed to handle sequential data like words in a sentence or events in a timeline by retaining memory of past inputs. The key feature of RNNs is their Hidden state, or Memory State, which retains information about previous inputs. Using the same parameters for all inputs simplifies the model, reducing complexity compared to other neural networks. They're great for tasks like understanding language, recognizing speech, and predicting future events based on past patterns, all because they can keep track of how things change over time.
Convolutional Neural Networks (CNNs) are a specialized type of neural network designed for processing structured grid data like images. They're made up of layers that automatically learn different aspects of pictures, like edges and textures. Each layer looks for specific features and passes that information along. CNNs significantly reduce the number of parameters compared to fully connected networks, making them highly effective for image and video recognition tasks, as well as other spatial data analysis applications.
Data scientists can apply machine learning algorithms to real-world problems by following this process:
- They need to understand the problem domain and define the objectives.
- They need to gather and preprocess relevant data, selecting features and handling missing values or outliers.
- They need to choose appropriate machine learning algorithms based on the problem type and data characteristics, fine-tuning parameters for optimal performance.
- After training the model, they need to evaluate its performance using metrics like accuracy or loss function.
- Finally, they can deploy the model into production and continuously monitor and update it as needed, ensuring it remains effective in solving real-world challenges.