
Introduction
The art of machine learning consists primarily of designing systems that accurately predict the outcomes of previously unencountered cases. This ability to work well with new data is called generalization. To achieve this, models learn from past data by identifying patterns and relationships within it. These patterns help the model make predictions on future data. Nevertheless, it is essential to reach this learning process equilibrium. A model can become quite familiar with the training data to the point of discerning even the noise and other non-essential elements, which leads to such a phenomenon as overfitting. An overfitted model may excel within the confines of the training data but will find it difficult to generalize beyond that data to make correct predictions about other new and unseen datasets. Bard becomes a new solution that sometimes may perform model training boringly with no apparent objective attaining situation. On the other hand, underfitting implies the presence of a model that is so basic that it isn’t capable of absorbing sufficient detail from the training set encasement of data. Because of this, the growing model, the number of which is relatively small after the first one, banal over-crowd growing and “new management” creates problems and deficits both with riving conception in and out. It is essential to avert overfitting and underfitting appeals to these practices to develop a proper machine-learning model. The aim is to achieve a scenario in which the model is neither complex nor straightforward; however, it falls within the parameters that will allow it to make correct predictions about new data.
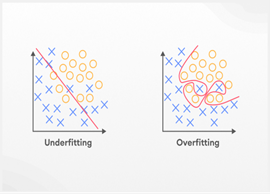
Overfitting
Overfitting refers to a situation where a model learns the training data too accurately, capturing even trivial inaccuracies, such as noise or outliers. As a result, the model becomes overfitted to the training data and loses its ability to generalize to new, unseen data. The model may perform excellently on the training data but fails severely with other data because it has not internalized the broad brushstrokes. Some modification is essential; overfitting impedes the development of reliable predictive models outside the clothed-in-data training environment.
Causes of Overfitting:
Causes of Overfitting:
- Too Complex Models: Overfitting often happens when models are too complex. For example, using a high-degree polynomial in regression tasks can make the model fit the training data almost perfectly, but it won't perform well on new data. Complex models have many parameters and can capture every detail, including irrelevant noise, which doesn't reflect the actual pattern.
- Insufficient Training Data: If insufficient training data exists, a complex model might be overfitting by focusing on the unique quirks of the limited data available. Instead of learning general patterns, the model memorizes the training examples.
- Excessive Training: Training a model for too long can also cause overfitting. As the model keeps learning, it might start memorizing specific details and noise in the training data instead of understanding the general patterns.
Overfitting Examples:
Underfitting
In machine learning, underfitting refers to a model's inability to capture trends due to its excessive simplicity. Hence, it performs poorly on familiar and unfamiliar data, lacking sufficient knowledge to make accurate forecasts. This is common in situations where the ML model cannot capture the actual complexity of the data. An underfitted model has no working principles that allow it to work on other datasets. Thus, it has no practical applications.
Causes of Underfitting:
- Too Simple Models: When the model is too basic for the complexity of data, it usually leads to underfitting. For instance, when a linear model is fitted on a complex, non-linear dataset, the model will result in underfitting since it is not flexible enough to accommodate the existing relationships in the data.
- Insufficient Features or Wrong Choice of Features: Underfitting can occur if the model doesn't have enough features or uses the wrong ones. The model will struggle to make correct predictions if the chosen features don’t represent the data well. This can happen if important details are omitted or irrelevant information is included, leading to poor predictions.
- Not Enough Training Time or Under-Trained Models: Underfitting can happen when the model is not given sufficient exposure or time to learn. The model may misconstrue the underlying patterns if the training duration is short or the number of iterations over the dataset is low. However, this issue is especially pronounced for advanced architectures such as deep learning, where more extended training periods are usually required for optimal model deployment.
Techniques to Reduce Underfitting:
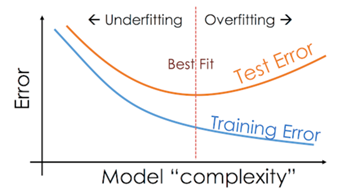
Identifying Overfitting and Underfitting:
Visualization Techniques:
Performance Metrics:

How do I avoid overfitting in my models?

Follow Us on
Scholarship
Women in Data Science
Veterans GI Bill
Employer Tution Assistance
Corporate Training Discount
Our Office
Copyright © 2025
Created with
