
Learning rate in neural networks
The learning rate is an essential hyperparameter in training neural networks, significantly influencing the model's performance. It determines how many adjustments are made to the model during each iteration. A high learning rate can lead to overfitting or cause the model to miss the global optimum, while a low learning rate may result in slow convergence or getting stuck in suboptimal local minima. However, the use of adaptive methods like Adam or RMSprop offers a promising avenue for improving training efficiency and overall model accuracy. Finding the right balance is crucial for practical model training. Learning rate schedules and cross-validation can further enhance this process.
Additionally, incorporating regularization and performing hyperparameter tuning are essential strategies for optimizing machine learning models.
Additionally, incorporating regularization and performing hyperparameter tuning are essential strategies for optimizing machine learning models.
What is the Learning Rate?
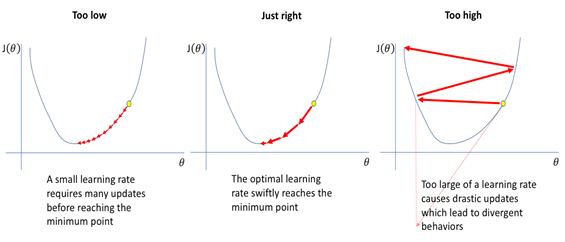
The learning rate is a crucial factor in training neural networks. It determines how much the model adjusts its "weights" during each training step. These weights are vital for the model's ability to make accurate predictions. During training, the model learns by modifying its weights based on the difference between its predictions and the actual results. The learning rate dictates the size of these adjustments. If the learning rate is too high, the model may excessively change its weights, potentially overlooking the optimal solution and resulting in unstable learning. In this case, the errors may not decrease, hindering the model's ability to learn effectively. Conversely, if the learning rate is too low, the model will make only minor adjustments, leading to slow learning. It may even become stuck and fail to find the best solution. Choosing the appropriate learning rate is vital for successful training. You can experiment with different rates or use techniques that adapt the learning rate as the model progresses. A well-chosen learning rate can help the model learn more quickly and perform better by reducing errors.
Importance of Learning Rate
The learning rate is critical to how quickly and effectively a neural network learns. A reasonable learning rate can help the model train faster. If the learning rate is too high, the model might take big jumps and miss the best solution, causing the training to become unstable. If it's too low, the model will take tiny steps, making learning slow and possibly getting stuck without finding the best solution. The learning rate also affects how well the model performs on new, unseen data. If set too high, the model may not learn enough from the training data, leading to underfitting (where the model doesn’t capture essential patterns). If it’s too low, the model might learn too much from the training data, leading to overfitting (where the model becomes too specific to the training data and performs poorly on new data). Choosing the correct learning rate is critical to fast and practical training, and techniques like adjusting the learning rate over time or using adaptive methods can help achieve the best results.
Effects of Learning Rate on Training
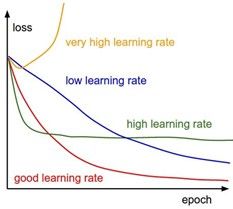
What are the best strategies for choosing a learning rate in deep learning?
Learning Rate Schedules:
Adaptive Learning Rates:
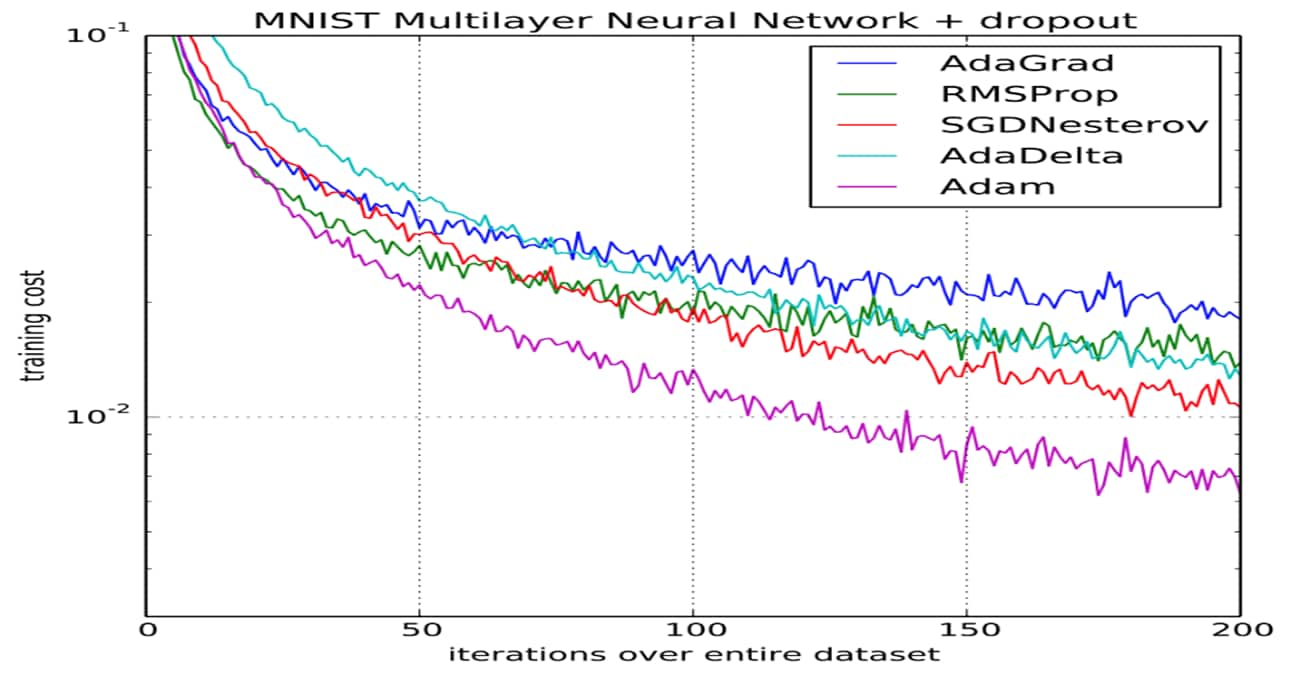
Techniques for Learning Rate Optimization:

Follow Us on
Scholarship
Women in Data Science
Veterans GI Bill
Employer Tution Assistance
Corporate Training Discount
Our Office
Copyright © 2025
Created with
